叙述
整理一下 openbmclapi 的项目的日志,将 log 文件导出为 db 文件,用于数据分析和开发API;
本来想导出 CSV 格式,用 Excel 分析数据,但 Excel 表最大支持 1,048,576 行 × 16,384 列;
又想到Excel 有个 Microsoft Access 或许支持大量日志数据,想了一下,好像不适合线上;
不用 Microsoft Access 主要是,博主不是很懂这个,对Mysql、PostgreSQL、SQLite更熟悉些;
经过思考,敲定了,本地用SQLite,线上用PostgreSQL,选 PostgreSQL 最大原因是想尝试其他数据库;
来看看我是怎么用 Python 解决这个问题吧 QWQ ~
第一次尝试
需要处理 176 个 .log 格式的文件,内容很多也复杂,只需提取固定格式的数据,其他都不要,生成 csv 文件.
实现目标:
- 支持输入目录(包含很多
.log文件) - 自动读取全部
.log文件 - 从每行中提取关键字段
- 输出到
.csv文件
日志示例:
# 来源于 openbmclapi_2025-05-01_020001_log.log 文件
::ffff:101.85.7.200 - - [01/May/2025:02:00:05 +0000] "GET /download/523fa864bde9ad0153d95cba82c8d155b3294968?name=523fa864bde9ad0153d95cba82c8d155b3294968&s=HM8-RY3WJWPO9_D0UnuVHUoCoEU&e=ma4q2xop HTTP/1.1" 206 11924 "-" "PCL2/2.9.3.50"提取字段:
| ip | 101.85.7.200 |
| datetime | 01/May/2025:02:00:05 +0000 |
| method | GET |
| path | /download/523fa864bde9ad0153d95cba82c8d155b3294968 |
| status | 206 |
| size | 11924 |
| user_agent | PCL2/2.9.3.50 |
Python 代码一
import os
import re
import csv
# 日志匹配正则
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
def extract_data_from_log(file_path):
"""从单个日志文件中提取符合格式的数据"""
results = []
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
match = LOG_PATTERN.search(line)
if match:
results.append(match.groupdict())
return results
def process_logs(input_dir, output_dir):
"""批量处理日志文件并导出CSV"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for file in os.listdir(input_dir):
if file.endswith(".log"):
log_path = os.path.join(input_dir, file)
csv_path = os.path.join(output_dir, file.replace(".log", ".csv"))
print(f"正在处理 {file} ...")
data = extract_data_from_log(log_path)
if data:
with open(csv_path, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=data[0].keys())
writer.writeheader()
writer.writerows(data)
print(f"导出成功: {csv_path} ({len(data)} 行)")
else:
print(f"未匹配到有效数据: {file}")
if __name__ == "__main__":
input_dir = input("请输入日志所在文件夹路径:").strip()
output_dir = input("请输入输出CSV文件夹路径:").strip()
process_logs(input_dir, output_dir)
Python 代码二
import os
import re
import csv
# 匹配日志格式的正则表达式
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
def extract_data_from_log(file_path):
"""从单个日志文件提取符合格式的数据"""
results = []
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
match = LOG_PATTERN.search(line)
if match:
data = match.groupdict()
data['filename'] = os.path.basename(file_path) # 记录来源文件名
results.append(data)
return results
def process_logs_to_one_csv(input_dir, output_csv):
"""批量处理日志文件并合并导出为一个CSV"""
all_data = []
for file in os.listdir(input_dir):
if file.endswith(".log"):
log_path = os.path.join(input_dir, file)
print(f"🔍 正在处理 {file} ...")
data = extract_data_from_log(log_path)
if data:
all_data.extend(data)
else:
print(f"未匹配到有效数据: {file}")
if all_data:
print(f"共提取 {len(all_data)} 行数据,正在写入 {output_csv} ...")
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['filename', 'ip', 'datetime', 'method', 'path', 'status', 'size', 'user_agent']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(all_data)
print(f"导出成功: {output_csv}")
else:
print("未提取到任何有效日志数据。")
if __name__ == "__main__":
input_dir = input("请输入日志文件夹路径:").strip()
output_csv = input("请输入导出 CSV 文件路径(例如 D:\\all.csv):").strip()
process_logs_to_one_csv(input_dir, output_csv)
思考
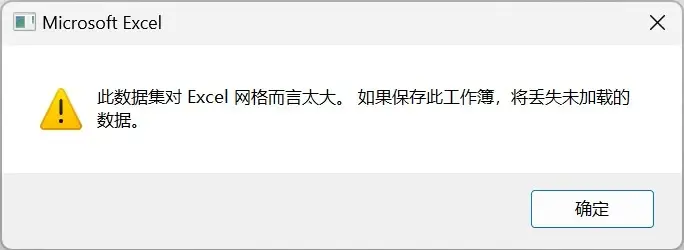
写了两个Python脚本发现,对于小日志文件,Excel 表可以支持,大日志文件且超过Excel 最大值:1,048,576 行就会提示:此数据集对于 Excel 网格而言太大。如果保存此工作簿,将丢失未加载的数据。
第二次尝试
既然 Excel 最大值不能超过1,048,576 行,那我直接用 SQLite,本地测试暂时用不到PostgreSQL;
SQLite 支持:
- 最大支持:140 TB
- 单表行数:约 2^64 行(约18,446,744,073,709,551,616 行)
- 单行数据大小:最大约 1 GB,最大 2^31-1 字节(编译时调整参数)
- 编译时参数调整,默认 2000 列,最大 32767 列(编译时调整参数)
- 索引数量:单表最多 64 个索引
改进目标
- 批量读取
.log文件 - 解析日志行(同样用正则)
- 写入 SQLite(自动建表、插入)
- 每条记录附带来源文件名
Python 代码
import os
import re
import sqlite3
# 日志正则
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
def init_db(db_path):
"""创建 SQLite 数据库和表"""
conn = sqlite3.connect(db_path)
c = conn.cursor()
c.execute("""
CREATE TABLE IF NOT EXISTS logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename TEXT,
ip TEXT,
datetime TEXT,
method TEXT,
path TEXT,
status INTEGER,
size INTEGER,
user_agent TEXT
)
""")
conn.commit()
return conn
def insert_data(conn, data):
"""批量插入日志数据"""
c = conn.cursor()
c.executemany("""
INSERT INTO logs (filename, ip, datetime, method, path, status, size, user_agent)
VALUES (:filename, :ip, :datetime, :method, :path, :status, :size, :user_agent)
""", data)
conn.commit()
def extract_data_from_log(file_path):
"""从单个日志文件提取数据"""
results = []
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
match = LOG_PATTERN.search(line)
if match:
record = match.groupdict()
record["filename"] = os.path.basename(file_path)
results.append(record)
return results
def process_logs_to_sqlite(input_dir, db_path):
"""批量处理日志文件写入SQLite"""
conn = init_db(db_path)
total = 0
for file in os.listdir(input_dir):
if file.endswith(".log"):
log_path = os.path.join(input_dir, file)
print(f"正在处理 {file} ...")
data = extract_data_from_log(log_path)
if data:
insert_data(conn, data)
total += len(data)
print(f"已导入 {len(data)} 条")
else:
print(f"无有效日志行: {file}")
conn.close()
print(f"所有日志处理完毕,共导入 {total} 条记录到 {db_path}")
if __name__ == "__main__":
input_dir = input("请输入日志文件夹路径:").strip()
db_path = input("请输入输出SQLite数据库路径(例如 D:\\logs.db):").strip()
process_logs_to_sqlite(input_dir, db_path)
SQLite 表结构
| id | INTEGER | 自增主键 |
| filename | TEXT | access_20250501.log |
| ip | TEXT | 101.85.7.200 |
| datetime | TEXT | 01/May/2025:02:00:05 +0000 |
| method | TEXT | GET |
| path | TEXT | /download/523fa864 |
| status | INTEGER | 206 |
| size | INTEGER | 11924 |
| user_agent | TEXT | PCL2/2.9.3.50 |
第三次尝试
看了代码,想了想,单线程有点慢,改成多线程,生成速度不得起飞咯~
思考片刻,改了一下功能:
| 多线程 | 并行处理多个 .log 文件,加快速度 |
| 断点续传 | 如果某 .log 文件已经导入过(对应表已存在),则自动跳过 |
| 单数据库 | 所有 .log 文件存入同一个 SQLite 数据库 |
| 每个文件一张表 | 表名根据文件名生成(自动去掉特殊字符) |
| 时间戳 | 把 [01/May/2025:02:00:05 +0000] 转为 UNIX 时间戳(秒)存储 |
| 其他结构保留 | 字段保持:ip, datetime, method, path, status, size, user_agent |
SQLite 表结构
| id | INTEGER | 主键 |
| ip | TEXT | 客户端 IP |
| datetime | INTEGER | UNIX 时间戳 |
| method | TEXT | HTTP 方法 |
| path | TEXT | 请求路径 |
| status | INTEGER | 状态码 |
| size | INTEGER | 响应大小 |
| user_agent | TEXT | UA 字符串 |
Python 代码
import os
import re
import sqlite3
import threading
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
# 日志匹配正则
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
# 月份映射(日志格式是 01/May/2025)
MONTH_MAP = {
'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6,
'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11, 'Dec': 12
}
lock = threading.Lock()
def parse_datetime_to_unix(dt_str):
"""
将日志中的时间字符串转为 UNIX 时间戳
比如:01/May/2025:02:00:05 +0000
"""
try:
date_part, tz = dt_str.split(' ')
day, month_str, year_time = date_part.split('/')
year, time_part = year_time.split(':', 1)
month = MONTH_MAP[month_str]
dt = datetime.strptime(f"{year}-{month:02d}-{day} {time_part}", "%Y-%m-%d %H:%M:%S")
# 忽略时区差异,假设为UTC时间
return int(time.mktime(dt.timetuple()))
except Exception:
return None
def extract_data_from_log(file_path):
"""从单个日志文件提取数据"""
results = []
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
match = LOG_PATTERN.search(line)
if match:
g = match.groupdict()
ts = parse_datetime_to_unix(g["datetime"])
if ts:
results.append({
"ip": g["ip"],
"datetime": ts,
"method": g["method"],
"path": g["path"],
"status": int(g["status"]),
"size": int(g["size"]),
"user_agent": g["user_agent"]
})
return results
def sanitize_table_name(filename):
"""生成安全的表名"""
name = os.path.splitext(filename)[0]
# 去除不合法字符,只保留字母数字和下划线
name = re.sub(r'[^0-9a-zA-Z_]', '_', name)
return name
def create_table_if_not_exists(conn, table_name):
"""创建表"""
with lock:
c = conn.cursor()
c.execute(f"""
CREATE TABLE IF NOT EXISTS "{table_name}" (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ip TEXT,
datetime INTEGER,
method TEXT,
path TEXT,
status INTEGER,
size INTEGER,
user_agent TEXT
)
""")
conn.commit()
def table_exists(conn, table_name):
"""检查表是否存在"""
c = conn.cursor()
c.execute("SELECT name FROM sqlite_master WHERE type='table' AND name=?", (table_name,))
return c.fetchone() is not None
def insert_data(conn, table_name, data):
"""插入数据"""
with lock:
c = conn.cursor()
c.executemany(
f'INSERT INTO "{table_name}" (ip, datetime, method, path, status, size, user_agent) '
f'VALUES (:ip, :datetime, :method, :path, :status, :size, :user_agent)',
data
)
conn.commit()
def process_single_file(db_path, log_file):
"""处理单个日志文件"""
conn = sqlite3.connect(db_path, check_same_thread=False)
table_name = sanitize_table_name(os.path.basename(log_file))
# 断点续传:若表已存在则跳过
if table_exists(conn, table_name):
print(f"已存在表 {table_name},跳过 {os.path.basename(log_file)}")
conn.close()
return 0
data = extract_data_from_log(log_file)
if not data:
print(f"无有效数据:{log_file}")
conn.close()
return 0
create_table_if_not_exists(conn, table_name)
insert_data(conn, table_name, data)
conn.close()
print(f"{table_name}: 导入 {len(data)} 条")
return len(data)
def process_logs_multithread(input_dir, db_path, max_workers=4):
"""多线程处理目录下所有日志"""
log_files = [
os.path.join(input_dir, f)
for f in os.listdir(input_dir)
if f.endswith(".log")
]
total = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(process_single_file, db_path, lf): lf for lf in log_files}
for future in as_completed(futures):
try:
total += future.result()
except Exception as e:
print(f"处理 {futures[future]} 出错: {e}")
print(f"\n处理完毕,共导入 {total} 条数据到 {db_path}")
if __name__ == "__main__":
input_dir = input("请输入日志文件夹路径:").strip()
db_path = input("请输入SQLite数据库路径(例如 D:\\logs.db):").strip()
threads = input("请输入并行线程数(默认 4):").strip()
threads = int(threads) if threads.isdigit() else 4
process_logs_multithread(input_dir, db_path, max_workers=threads)
实现效果
- 并行扫描日志文件
- 每个文件创建一个独立表(如
openbmclapi_2025_03_13_020002_log) - 若表已存在则自动跳过(断点续传)
- 日志时间自动转为 Unix 时间戳(整数)
第四次尝试
每张数据表都是 “openbmclapi_2025_03_13_020002_log” 这种格式,有点小长。移除 “openbmclapi_” 和 “020002_log”,并添加"log"前缀。就会得到 “log_2025_03_13”,“log” 表示日志标识,“2025_03_13” 表示日期。这样既能避免 “前缀不能是数字”,符合命名规则;
改进目标
- 每张表改成这种格式:“
log_xxxx_xx_xx”,比如:“log_2025_03_13” - 移除 “
openbmclapi_” 和 “020002_log” 前后缀,只保留日期,并添加"log"前缀,符合命名规则 - 添加导入进度条(tqdm),方便查看进度
- 导入后建立索引,以加速查询
| 单 SQLite 数据库 | 所有 .log 数据集中存储 |
| 每个文件独立表 | 表名格式为 log_2025_03_13注:从文件名中提取日期 |
| 自动建表 + 索引 | 每个表自动建立索引 idx_datetime |
| 多线程并行导入 | 默认 4 线程,可自定义 8 线程 |
| 断点续传 | 已导入表自动跳过 |
| 时间戳存储 | datetime 字段为 UNIX 时间戳(整数) |
| 实时进度条 | 使用 tqdm 显示导入进度 |
Python 代码
import os
import re
import sqlite3
import threading
import time
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
# -------------------------------
# 日志匹配规则
# -------------------------------
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
MONTH_MAP = {
'Jan': 1, 'Feb': 2, 'Mar': 3, 'Apr': 4, 'May': 5, 'Jun': 6,
'Jul': 7, 'Aug': 8, 'Sep': 9, 'Oct': 10, 'Nov': 11, 'Dec': 12
}
lock = threading.Lock()
# -------------------------------
# 工具函数
# -------------------------------
def parse_datetime_to_unix(dt_str):
"""将日志中的时间字符串转为 UNIX 时间戳"""
try:
date_part, tz = dt_str.split(' ')
day, month_str, year_time = date_part.split('/')
year, time_part = year_time.split(':', 1)
month = MONTH_MAP[month_str]
dt = datetime.strptime(f"{year}-{month:02d}-{day} {time_part}", "%Y-%m-%d %H:%M:%S")
return int(time.mktime(dt.timetuple()))
except Exception:
return None
def extract_data_from_log(file_path):
"""解析单个日志文件"""
results = []
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
for line in f:
match = LOG_PATTERN.search(line)
if match:
g = match.groupdict()
ts = parse_datetime_to_unix(g["datetime"])
if ts:
results.append({
"ip": g["ip"],
"datetime": ts,
"method": g["method"],
"path": g["path"],
"status": int(g["status"]),
"size": int(g["size"]),
"user_agent": g["user_agent"]
})
return results
def extract_table_name_from_filename(filename):
"""
从文件名中提取日期部分,例如:
openbmclapi_2025-03-13_020002_log.log → log_2025_03_13
"""
name = os.path.splitext(filename)[0]
m = re.search(r'(\d{4})[-_](\d{2})[-_](\d{2})', name)
if m:
year, month, day = m.groups()
return f"log_{year}_{month}_{day}"
else:
# fallback 兜底
name = re.sub(r'[^0-9a-zA-Z_]', '_', name)
return f"log_{name}"
# -------------------------------
# SQLite 操作函数
# -------------------------------
def table_exists(conn, table_name):
"""检查表是否存在"""
c = conn.cursor()
c.execute("SELECT name FROM sqlite_master WHERE type='table' AND name=?", (table_name,))
return c.fetchone() is not None
def create_table_and_index(conn, table_name):
"""创建表和索引"""
with lock:
c = conn.cursor()
c.execute(f"""
CREATE TABLE IF NOT EXISTS "{table_name}" (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ip TEXT,
datetime INTEGER,
method TEXT,
path TEXT,
status INTEGER,
size INTEGER,
user_agent TEXT
)
""")
# 创建索引加速查询
c.execute(f"CREATE INDEX IF NOT EXISTS idx_datetime_{table_name} ON '{table_name}' (datetime);")
conn.commit()
def insert_data(conn, table_name, data):
"""插入多条记录"""
with lock:
c = conn.cursor()
c.executemany(
f'INSERT INTO "{table_name}" (ip, datetime, method, path, status, size, user_agent) '
f'VALUES (:ip, :datetime, :method, :path, :status, :size, :user_agent)',
data
)
conn.commit()
# -------------------------------
# 主任务函数
# -------------------------------
def process_single_file(db_path, log_file):
"""处理单个日志文件"""
conn = sqlite3.connect(db_path, check_same_thread=False)
filename = os.path.basename(log_file)
table_name = extract_table_name_from_filename(filename)
# 断点续传
if table_exists(conn, table_name):
conn.close()
return 0, table_name, True
data = extract_data_from_log(log_file)
if not data:
conn.close()
return 0, table_name, False
create_table_and_index(conn, table_name)
insert_data(conn, table_name, data)
conn.close()
return len(data), table_name, False
def process_logs_multithread(input_dir, db_path, max_workers=4):
"""多线程处理所有日志文件"""
log_files = [
os.path.join(root, f)
for root, _, files in os.walk(input_dir)
for f in files if f.endswith(".log")
]
total = 0
skipped = 0
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(process_single_file, db_path, lf): lf for lf in log_files}
for future in tqdm(as_completed(futures), total=len(futures), desc="导入进度", ncols=100):
try:
count, table_name, was_skipped = future.result()
if was_skipped:
skipped += 1
else:
total += count
except Exception as e:
print(f"处理 {futures[future]} 出错: {e}")
print(f"\n导入完成,共导入 {total} 条记录,跳过 {skipped} 个已存在表。")
print(f"数据库文件: {db_path}")
# -------------------------------
# 程序入口
# -------------------------------
if __name__ == "__main__":
input_dir = input("请输入日志文件夹路径:").strip()
db_path = input("请输入SQLite数据库路径(例如 D:\\logs.db):").strip()
threads = input("请输入并行线程数(默认 4):").strip()
threads = int(threads) if threads.isdigit() else 4
process_logs_multithread(input_dir, db_path, max_workers=threads)
实现效果
假设日志文件名
openbmclapi_2025-03-13_020002_log.log
openbmclapi_2025-03-14_031245_log.log
openbmclapi_2025-03-15_041556_log.log生成的 SQLite 表为
log_2025_03_13
log_2025_03_14
log_2025_03_15且每个表自动带有索引:
idx_datetime_log_2025_03_13
idx_datetime_log_2025_03_14
idx_datetime_log_2025_03_15第四次尝试
偷懒一下,SQLite文件输出路径要手动填写文件名(比如:D:\logs.db),改成文件名固定(不用手动填文件名),但输出地址依然要手动填写~
想了想,文件不可能只存不读吧,哪就添加一个“合并查询视图” 功能,创建一个 all_logs_view,可一次性跨所有表查询,不用一个个适配
改进目标
- 多线程并行处理
.log文件 - 断点续传:自动跳过已导入的文件
- 自动生成表名:
openbmclapi_2025-03-13_020002_log.log→ 表名log_2025_03_13 - SQLite 数据库存储固定为:
openbmclapi.db - 用户只需输入“日志文件目录”
- 数据库存放路径自动拼接输出路径
- 日期自动转为 Unix 时间戳(方便按日期筛选)
- 自动生成合并视图
all_logs_view,支持跨表查询 - 自动创建索引,提升查询性能
- 导入进度条(
tqdm)
Python 代码
import os
import re
import sqlite3
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
from datetime import datetime
# 固定数据库文件名
DB_NAME = "openbmclapi.db"
# 日志匹配正则
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d\.]+) - - \[(?P<datetime>[^\]]+)\] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d\.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
# 日期解析函数
def parse_datetime_to_unix(dt_str: str) -> int:
try:
# 格式如 "01/May/2025:02:00:05 +0000"
return int(datetime.strptime(dt_str.split(" ")[0], "%d/%b/%Y:%H:%M:%S").timestamp())
except Exception:
return 0
# 提取表名:log_YYYY_MM_DD
def extract_table_name(filename: str) -> str:
match = re.search(r"_(\d{4})-(\d{2})-(\d{2})_", filename)
if match:
return f"log_{match.group(1)}_{match.group(2)}_{match.group(3)}"
return "log_unknown"
# 提取日志数据
def extract_log_data(file_path):
rows = []
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
for line in f:
m = LOG_PATTERN.search(line)
if m:
gd = m.groupdict()
rows.append((
gd["ip"],
parse_datetime_to_unix(gd["datetime"]),
gd["method"],
gd["path"],
int(gd["status"]),
int(gd["size"]),
gd["user_agent"],
os.path.basename(file_path)
))
return rows
# 建表(如果不存在)
def create_table_if_not_exists(conn, table_name):
conn.execute(f"""
CREATE TABLE IF NOT EXISTS {table_name} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ip TEXT,
datetime INTEGER,
method TEXT,
path TEXT,
status INTEGER,
size INTEGER,
user_agent TEXT,
filename TEXT
)
""")
# 创建索引(提升查询速度)
conn.execute(f"CREATE INDEX IF NOT EXISTS idx_{table_name}_datetime ON {table_name}(datetime)")
conn.execute(f"CREATE INDEX IF NOT EXISTS idx_{table_name}_ip ON {table_name}(ip)")
conn.commit()
# 写入数据库
def insert_logs(conn, table_name, rows):
if not rows:
return
conn.executemany(f"""
INSERT INTO {table_name} (ip, datetime, method, path, status, size, user_agent, filename)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", rows)
conn.commit()
# 检查是否已导入该文件
def is_file_imported(conn, filename):
cursor = conn.execute(
"SELECT name FROM sqlite_master WHERE type='table' AND name LIKE 'log_%'"
)
for (table_name,) in cursor.fetchall():
res = conn.execute(f"SELECT 1 FROM {table_name} WHERE filename=? LIMIT 1", (filename,)).fetchone()
if res:
return True
return False
# 处理单个日志文件
def process_single_log(conn_path, file_path):
conn = sqlite3.connect(conn_path)
filename = os.path.basename(file_path)
if is_file_imported(conn, filename):
conn.close()
return f"跳过(已导入): {filename}"
table_name = extract_table_name(filename)
create_table_if_not_exists(conn, table_name)
rows = extract_log_data(file_path)
insert_logs(conn, table_name, rows)
conn.close()
return f"已导入: {filename}({len(rows)} 条)"
# 创建合并视图
def create_combined_view(conn):
cursor = conn.execute("SELECT name FROM sqlite_master WHERE type='table' AND name LIKE 'log_%'")
tables = [row[0] for row in cursor.fetchall()]
if not tables:
return
union_sql = " UNION ALL ".join([f"SELECT * FROM {t}" for t in tables])
conn.execute("DROP VIEW IF EXISTS all_logs_view")
conn.execute(f"CREATE VIEW all_logs_view AS {union_sql}")
conn.commit()
# 主函数
def main():
input_dir = input("请输入日志文件夹路径:").strip()
output_dir = input("请输入输出文件夹路径(用于存放 openbmclapi.db):").strip()
db_path = os.path.join(output_dir, DB_NAME)
os.makedirs(output_dir, exist_ok=True)
conn = sqlite3.connect(db_path)
conn.close()
log_files = [os.path.join(input_dir, f) for f in os.listdir(input_dir) if f.endswith(".log")]
print(f"共检测到 {len(log_files)} 个日志文件\n")
with ThreadPoolExecutor(max_workers=8) as executor:
futures = {executor.submit(process_single_log, db_path, f): f for f in log_files}
for _ in tqdm(as_completed(futures), total=len(futures), desc="导入进度", unit="文件"):
pass
# 创建合并视图
conn = sqlite3.connect(db_path)
create_combined_view(conn)
conn.close()
print(f"\n全部处理完成!数据库文件已生成:{db_path}")
print("统一查询视图:all_logs_view 已创建,可跨表查询。")
if __name__ == "__main__":
main()
第五次尝试
不行,大问题!
导出的数据库查看后,日期对不上,日志数据是从2025-03-13 - 2025-11-02,导出只有16张表,且发现大部分数据表是空表,只有几张是有数据,但好像也不完整,即 “部分空表、表数量不对”.
思考片刻,好像是:多线程并发写入同一个 SQLite 文件,会触发互锁机制
SQLite 的锁机制是整个数据库级别的(非表级别):
- 多个连接 同时写入一个
.db文件,哪怕写不同表,SQLite 仍会使用RESERVED或EXCLUSIVE锁; - 如果线程 A 正在
COMMIT,线程 B 会阻塞甚至报错; - 多线程时,Python 的
sqlite3默认不会等待太久,可能出现:- 写入中断
- 空表
- 数据丢失
- 表未 commit 就关闭连接
最后还是换成单线程,避免多线程导致互锁(有时候 聪明 也会出错)
Python 代码
import os
import re
import sqlite3
from datetime import datetime
from tqdm import tqdm
# 固定数据库文件名
DB_NAME = "openbmclapi.db"
# 日志匹配正则
LOG_PATTERN = re.compile(
r'::ffff:(?P<ip>[\d.]+) - - \[(?P<datetime>[^]]+)] '
r'"(?P<method>\S+) (?P<path>\S+)(?:\?\S*)? HTTP/[\d.]+" '
r'(?P<status>\d+) (?P<size>\d+) "-" "(?P<user_agent>[^"]+)"'
)
# 将 "01/May/2025:02:00:05 +0000" 转为 UNIX 时间戳
def parse_datetime_to_unix(dt_str: str) -> int:
try:
dt_clean = dt_str.split(" ")[0]
return int(datetime.strptime(dt_clean, "%d/%b/%Y:%H:%M:%S").timestamp())
except Exception:
return 0
# 从文件名提取表名:log_YYYY_MM_DD
def extract_table_name(filename: str) -> str:
match = re.search(r"_(\d{4})-(\d{2})-(\d{2})_", filename)
if match:
return f"log_{match.group(1)}_{match.group(2)}_{match.group(3)}"
return "log_unknown"
# 提取日志数据
def extract_log_data(file_path):
rows = []
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
for line in f:
m = LOG_PATTERN.search(line)
if m:
gd = m.groupdict()
rows.append((
gd["ip"],
parse_datetime_to_unix(gd["datetime"]),
gd["method"],
gd["path"],
int(gd["status"]),
int(gd["size"]),
gd["user_agent"],
os.path.basename(file_path)
))
return rows
# 创建表(如果不存在)
def create_table_if_not_exists(conn, table_name):
conn.execute(f"""
CREATE TABLE IF NOT EXISTS {table_name} (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ip TEXT,
datetime INTEGER,
method TEXT,
path TEXT,
status INTEGER,
size INTEGER,
user_agent TEXT,
filename TEXT
)
""")
conn.execute(f"CREATE INDEX IF NOT EXISTS idx_{table_name}_datetime ON {table_name}(datetime)")
conn.execute(f"CREATE INDEX IF NOT EXISTS idx_{table_name}_ip ON {table_name}(ip)")
conn.commit()
# 检查是否已导入
def is_file_imported(conn, filename):
cursor = conn.execute("SELECT name FROM sqlite_master WHERE type='table' AND name LIKE 'log_%'")
for (table_name,) in cursor.fetchall():
res = conn.execute(f"SELECT 1 FROM {table_name} WHERE filename=? LIMIT 1", (filename,)).fetchone()
if res:
return True
return False
# 单线程处理:一个接一个导入
def process_logs_serial(input_dir, db_path):
conn = sqlite3.connect(db_path)
log_files = [f for f in os.listdir(input_dir) if f.endswith(".log")]
for filename in tqdm(log_files, desc="导入进度", unit="文件"):
file_path = os.path.join(input_dir, filename)
if is_file_imported(conn, filename):
tqdm.write(f"跳过(已导入): {filename}")
continue
table_name = extract_table_name(filename)
rows = extract_log_data(file_path)
if not rows:
tqdm.write(f"无有效数据: {filename}")
continue
create_table_if_not_exists(conn, table_name)
conn.executemany(f"""
INSERT INTO {table_name}
(ip, datetime, method, path, status, size, user_agent, filename)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", rows)
conn.commit()
tqdm.write(f"已导入: {filename}({len(rows)} 条)")
conn.close()
# 创建跨表查询视图
def create_combined_view(db_path):
conn = sqlite3.connect(db_path)
cursor = conn.execute("SELECT name FROM sqlite_master WHERE type='table' AND name LIKE 'log_%'")
tables = [row[0] for row in cursor.fetchall()]
if not tables:
print("没有可用的日志表,未创建视图。")
conn.close()
return
union_sql = " UNION ALL ".join([f"SELECT * FROM {t}" for t in tables])
conn.execute("DROP VIEW IF EXISTS all_logs_view")
conn.execute(f"CREATE VIEW all_logs_view AS {union_sql}")
conn.commit()
conn.close()
print("统一查询视图 all_logs_view 已创建。")
def main():
input_dir = input("请输入日志文件夹路径:").strip()
output_dir = input("请输入输出文件夹路径:").strip()
os.makedirs(output_dir, exist_ok=True)
db_path = os.path.join(output_dir, DB_NAME)
print(f"输出数据库:{db_path}")
process_logs_serial(input_dir, db_path)
create_combined_view(db_path)
print(f"\n全部导入完成!数据库文件位于:{db_path}")
if __name__ == "__main__":
main()
改动说明
| 多线程 | 移除,改为单线程顺序执行 |
| 锁表问题 | 消除(所有写入同一连接) |
| 表结构 | 保留 log_YYYY_MM_DD 命名 |
| 时间戳 | 转为 UNIX 时间戳 |
| 断点续传 | 检查已导入文件跳过 |
| 跨表视图 | 自动重建 all_logs_view |
验证查询
-- 查询日志表总数
SELECT COUNT(*) FROM sqlite_master WHERE type='table' AND name LIKE 'log_%';
-- 查询 2025-03-13 的数据
SELECT * FROM log_2025_03_13 LIMIT 5;
-- 跨表查询近7天访问记录
SELECT * FROM all_logs_view
WHERE datetime > strftime('%s', 'now', '-7 day');待完成
- 转换为PostgreSQL(上面测试使用的是SQLite,线上需要换成PostgreSQL)
- API编写
- API部署
- API测试
- API上线
- Web界面设计(Next)
- Web设计
- Web编写
- Web测试
- Web上线
结束
有点弃坑QAQ

